Lighting Tokens Beat Style Labels for Multi-Shot Continuity
"Cinematic" tells the model nothing. A five-word lighting token repeated verbatim across every prompt in a sequence does the work. Here's how to build one.
Why lighting drift happens
Shot one: warm golden hour backlight, long shadows, gorgeous. Shot two with slightly different phrasing: sun is overhead now. Shot three: flat overcast.
The model didn't get worse. Every generation call is stateless, no memory of the previous clip's lighting. Every prompt is a fresh ask. If your lighting language varies by even a word, interpretation varies.
Style labels like "cinematic" or "dramatic" don't fix this. They describe a vibe without specifying color temperature, direction, or quality. A lighting token specifies all three in a short, repeatable phrase.

Building a token set
Write three to five tokens before any shot prompts. Each names color temperature, direction, and quality in under twelve words:
warm amber sidelight from camera-left, long low shadows, no overhead fillovercast soft diffusion, flat white-gray light, no hard shadowsneon cyan rim light, dark environment, wet pavement reflectionsmotivated 3200K key from window, warm falloff across face, soft shadow side
Store them as constants. Inject by string interpolation, never retype. One typo creates a different lighting interpretation.
Where to place the token
At the end of environment description, before camera movement. This stops the model from trading lighting detail against subject detail:
1[subject action], [environment], [lighting token], [camera movement]
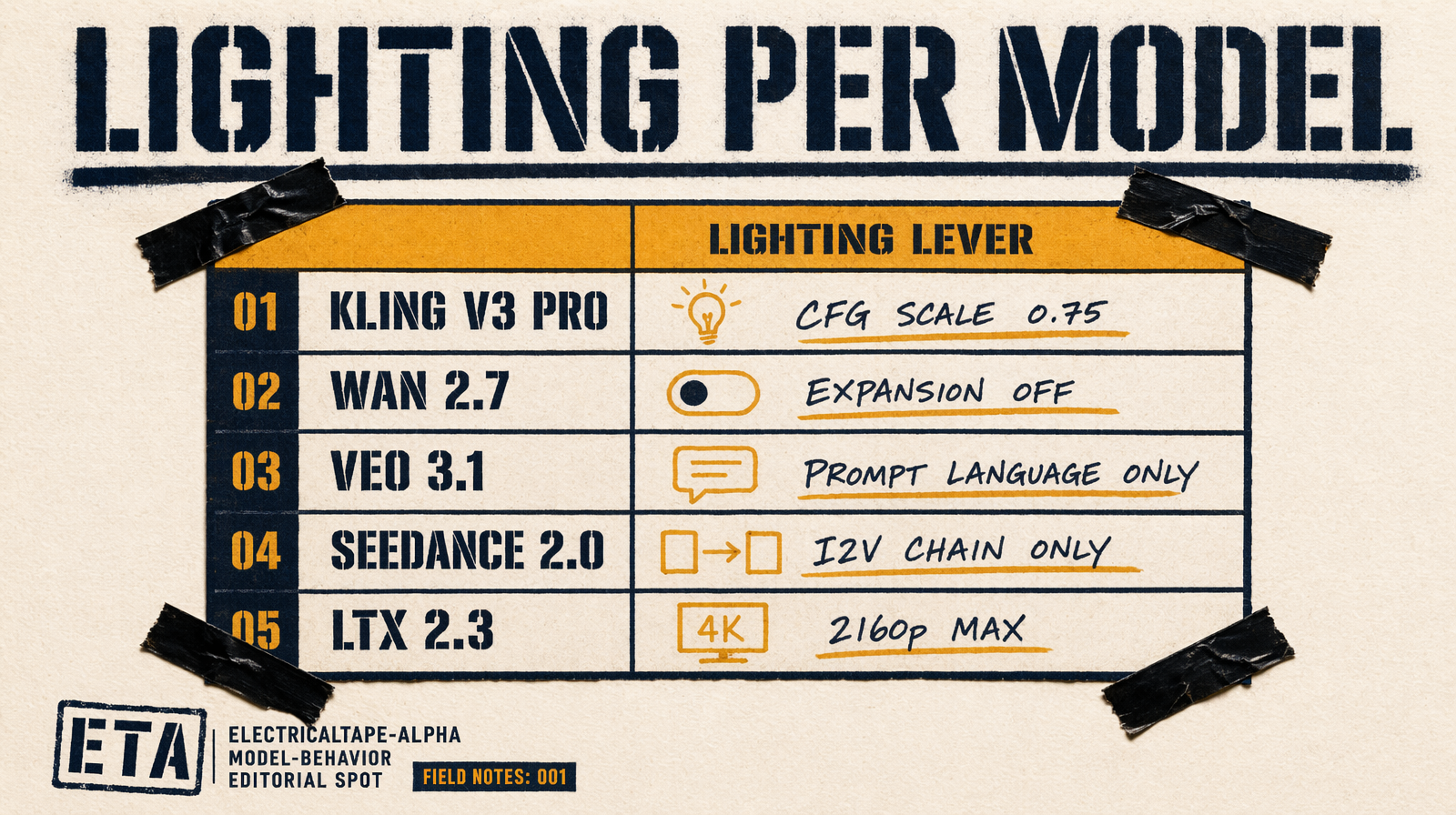
Model-specific behavior
Kling v3 Pro has negative_prompt and cfg_scale. For tight lighting, set cfg_scale: 0.75 to force the token, push drift words into the negative: "daylight, overexposed, flat lighting".
Wan 2.7 has enable_prompt_expansion on by default. The expander can paraphrase or drop your lighting token. Set it to false for multi-shot. Check actual_prompt in the response to verify your token survived.
Veo 3.1 has no end_image_url, prompt language only. Veo responds well to motivated key from 45° camera-left, warm 3200K.
Seedance 2.0 T2V has no end_image_url. I2V does (bytedance/seedance-2.0/image-to-video). Extract the last clean frame, pass to N+1's I2V call with the same token.
LTX 2.3 runs up to 2160p. For high-res lighting work it's the strongest choice.
A five-shot worked example
Night rooftop chase, neon palette. One lighting token, reused across every shot:
1LIGHTING = "neon cyan rim light, dark environment, wet pavement reflections"2SUBJECT = "a courier in a dark hooded jacket, late 20s, short black hair"34shots = [5 {"prompt": f"{SUBJECT} stands at edge of rooftop, city sprawl below, {LIGHTING}, wide establishing, camera static", "duration": 6},6 {"prompt": f"{SUBJECT} starts running toward frame-right, wind in jacket, {LIGHTING}, camera tracking low behind subject", "duration": 5},7 {"prompt": f"{SUBJECT} leaps across rooftop gap, mid-air, rooftops to horizon, {LIGHTING}, wide Dutch angle", "duration": 4},8 {"prompt": f"close on boots landing hard, puddle splash, {LIGHTING}, macro ground-level", "duration": 3},9 {"prompt": f"{SUBJECT} runs away from camera, silhouette against distant skyline, {LIGHTING}, slow pull-back", "duration": 6},10]1112for shot in shots:13 fal_client.run("fal-ai/wan/v2.7/text-to-video", arguments={14 "prompt": shot["prompt"],15 "negative_prompt": "daylight, overexposed, flat lighting, different clothing",16 "resolution": "1080p",17 "aspect_ratio": "16:9",18 "duration": shot["duration"],19 "enable_prompt_expansion": False,20 "seed": 42,21 })
LIGHTING and SUBJECT constants appear verbatim in all five prompts. Seed fixed. Expansion off. That's multi-shot discipline.

The failure mode to catch before credits burn
Render shot one. Save first and last frames as JPEGs. Use a color picker to sample dominant hue on three patches: sky, subject rim, ground. Record RGB values.
Render shot two with the same token. Sample again.
If hue differs by more than ~30-40 RGB units, the token isn't holding. Common causes: Wan's prompt expansion is on, the token was paraphrased, or a conflicting lighting word snuck into the environment description. Fix the prompt before generating shots three through five.
Two minutes of work, one or two extra renders. Finding out at shot five that all four drifted costs the whole batch.