Exponential Backoff for Transient fal API Errors
A tiny retry wrapper that handles the most common transient errors without burning a single extra generation.
Retry, but not on everything
The cheapest bug is retrying a 400 a dozen times. A 400 means bad input. Retrying it costs time and, if you hit a partial generation path, money.
Retry only on the transient class.

- 408 request timeout
- 429 too many requests (concurrency or rate limit)
- 500, 502, 503, 504 server errors
- Network layer: DNS, TCP reset, TLS handshake, connection closed mid response
Everything else is a code smell, not a flake. Do not retry 401, 403, 404, 422.
The algorithm in one paragraph
Start with a short base delay (500 ms). Double after each failure. Add random jitter so callers do not wake up together. Cap the delay. Cap the total attempts.
Formula: sleep = min(base * 2^attempt, cap) * random(0.5, 1.5).
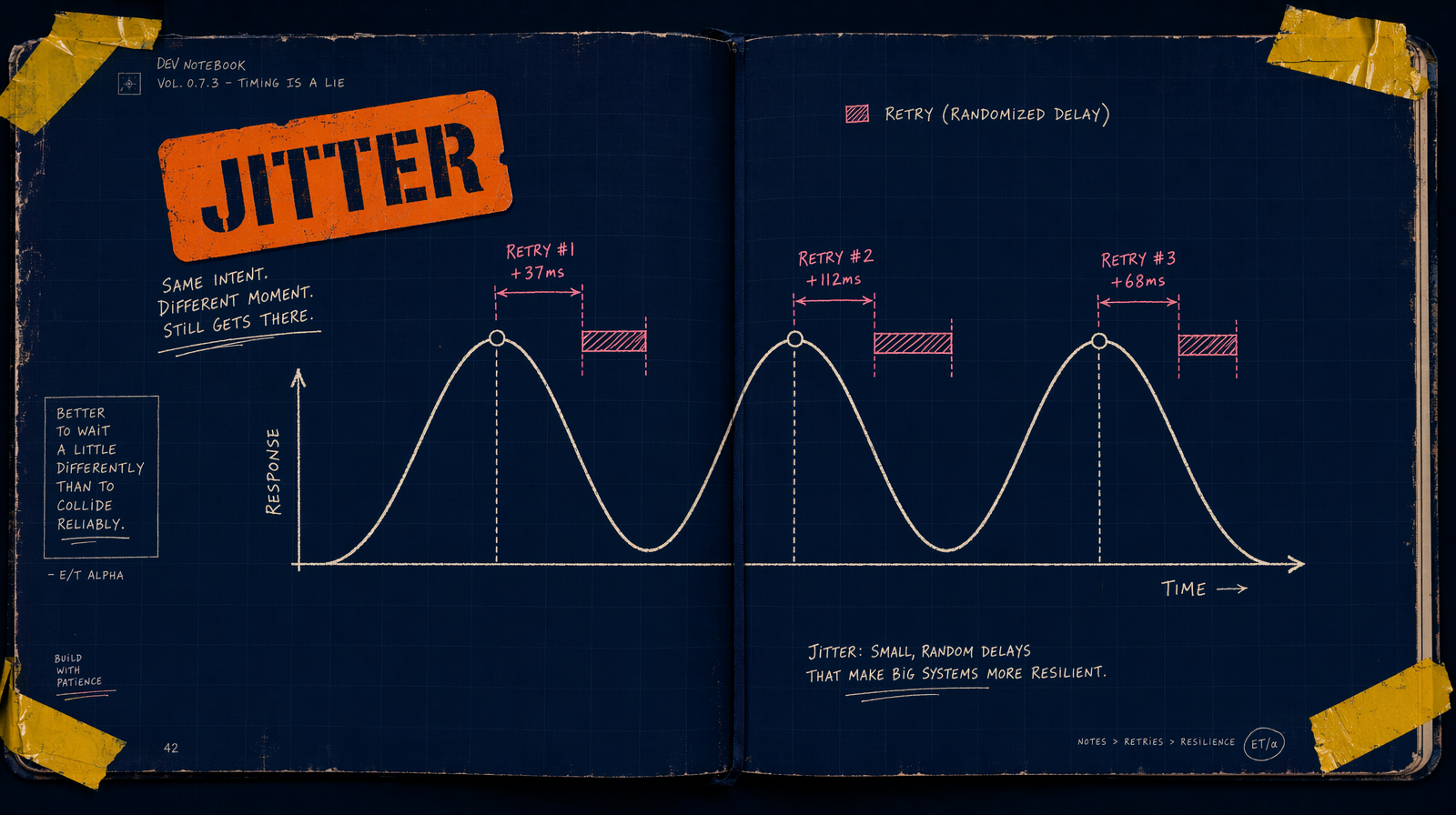
Without jitter, every caller that failed at the same moment retries at the same moment. With it, they spread.
TypeScript wrapper
1type Fn<T> = () => Promise<T>;23interface BackoffOptions {4 maxAttempts?: number;5 baseMs?: number;6 capMs?: number;7 isRetryable?: (err: unknown) => boolean;8}910const defaultRetryable = (err: unknown) => {11 const e = err as { status?: number; code?: string };12 if (e?.code === "ECONNRESET" || e?.code === "ETIMEDOUT") return true;13 if (e?.status === 408 || e?.status === 429) return true;14 if (e?.status && e.status >= 500 && e.status < 600) return true;15 return false;16};1718export async function withBackoff<T>(19 fn: Fn<T>,20 opts: BackoffOptions = {},21): Promise<T> {22 const { maxAttempts = 5, baseMs = 500, capMs = 15_000, isRetryable = defaultRetryable } = opts;23 let attempt = 0;24 while (true) {25 try {26 return await fn();27 } catch (err) {28 attempt += 1;29 if (attempt >= maxAttempts || !isRetryable(err)) throw err;30 const raw = Math.min(baseMs * 2 ** (attempt - 1), capMs);31 await new Promise((r) => setTimeout(r, raw * (0.5 + Math.random())));32 }33 }34}
Wrap your fal calls with it.
1const result = await withBackoff(() =>2 fal.subscribe("fal-ai/pixverse/v6/text-to-video", {3 input: { prompt: "A fox trotting through snow, wide shot", duration: 5 },4 }),5);
Pixverse v6 starting at $0.03/sec (360p no audio, scaling to $0.12/sec for 1080p with audio) is the right tester. A 5 second draft at 360p no audio is $0.15.
429 specifically
A 429 means concurrency. The retry works eventually, but the better fix is not firing every job at once. Put a p-queue in front. Move long jobs to fal.queue.submit with a webhook so workers are not held on subscribe.
Do not retry a running job
The most expensive mistake is retrying a job that is already running because the HTTP connection dropped.
1const { request_id } = await fal.queue.submit("fal-ai/wan/v2.7/text-to-video", {2 input: { prompt: "...", duration: 5 },3});45// save request_id BEFORE polling6await db.insert("generations", { request_id, status: "IN_QUEUE" });
If subscribe fails with a network error mid job, grab the request id and resume with fal.queue.status and fal.queue.result. Do not resubmit.
Python version
1import random, time, httpx, fal_client23def with_backoff(fn, *, max_attempts=5, base=0.5, cap=15.0):4 attempt = 05 while True:6 try:7 return fn()8 except httpx.HTTPStatusError as e:9 s = e.response.status_code10 retry = s in (408, 429) or 500 <= s < 60011 except (httpx.TimeoutException, httpx.NetworkError):12 retry = True13 else:14 retry = False1516 attempt += 117 if attempt >= max_attempts or not retry:18 raise19 time.sleep(min(base * (2 ** (attempt - 1)), cap) * (0.5 + random.random()))
Caps that make sense
Five attempts, cap 15 seconds, base 500 ms. Roughly a minute of retry budget, long enough to ride through transient dips without burning a human watching a spinner. Cut to three attempts if your UX cannot tolerate a minute. Do not push past eight.